About CTW
CTW is a Tokyo-based gaming company that operates G123, one of the world's largest HTML5 browser gaming platforms. G123 serves players across more than 200 countries and regions with free-to-play games built on popular anime and manga IP, partnering with over 25 intellectual property holders.
Data and AI are essential for CTW. The platform feeds real-time user segments to ad networks like Google, Facebook, and TikTok for targeting, serves Business Insights(BI) dashboards to dozens of game publisher partners, and runs an AI agent that lets business users and stakeholders query the entire data assets conversationally. When data is stale, or queries are slow, ad spend is wasted, affecting partner trust, and rendering the AI agent unusable.
The bottleneck wasn't whether TiDB or the lakehouse could keep up — it was whether either was the right shape for the workload.
Key takeaway · Workload fit, not vendor choice
The challenge
CTW's data infrastructure needed to serve three workloads: customer-facing audience segmentation for ad platforms, a company-wide BI layer for internal and customer use, and an AI-powered analytics agent. As the platform scaled, the first two hit walls that prevented the third from being viable at all.
Audience Segmentation Bottleneck on TiDB
CTW's audience table is one of the most critical tables in its data stack. It tracks each user's current segment — such as new users, returning users, high-value users, or churned users — and feeds that data to advertising platforms for lookalike modeling and retargeting. When a user's segment changes, that update needs to propagate quickly so downstream targeting reflects the latest user state.
CTW originally stored this table in TiDB. TiDB served point queries well and supported low-latency reads for online recommendation use cases. However, as audience sizes and refresh frequency increased, large-scale segment updates became increasingly inefficient. Each refresh involved removing outdated memberships and writing the latest segment state back into the table. For segments containing millions of users, a refresh cycle takes many hours, making it harder for the table to reflect the most current user state.
As CTW launched more games and acquired more users, segment sizes expanded and refresh cycles became more time intensive. TiDB could be scaled to handle the workload, and additional nodes brought meaningful performance gains. However, for CTW's large, frequently refreshed audience segments, the team concluded that this was not the most cost-effective serving path. The issue was less about whether TiDB could support the workload, and more about workload fit: an OLTP-oriented engine was no longer the most efficient choice for this style of large-scale segment refresh.
BI Dashboard Latency on the Original Lakehouse Access Path
CTW's BI layer serves dashboards to both internal teams and external game publisher partners. The underlying data is maintained in Delta Lake on Databricks, where hundreds of ETL jobs run each day. In the original architecture, interactive dashboard queries were served through live access to the lakehouse.
As dashboard usage grew, this access pattern became largely inefficient for highly concurrent, latency-sensitive BI workloads. During peak hours, query concurrency increased, dashboard requests began to queue, and some pages took tens of seconds to load — especially during periods when both internal teams and external partners required timely access to data.
CTW could continue scaling compute to support this workload, but the cost-efficiency became increasingly impractical for interactive BI serving at higher concurrencies. The team concluded that the issue was not any single product in isolation, but workload fit: the original lakehouse access path remained well suited to ETL and large-scale data processing, but it was no longer the most efficient serving path for interactive BI at CTW's scale.
The solution
CTW migrated both workloads onto PhoenixAI (powered by the open-source StarRocks project), using different table types and access patterns for each use case. This also laid the foundation for their AI analytics agent.
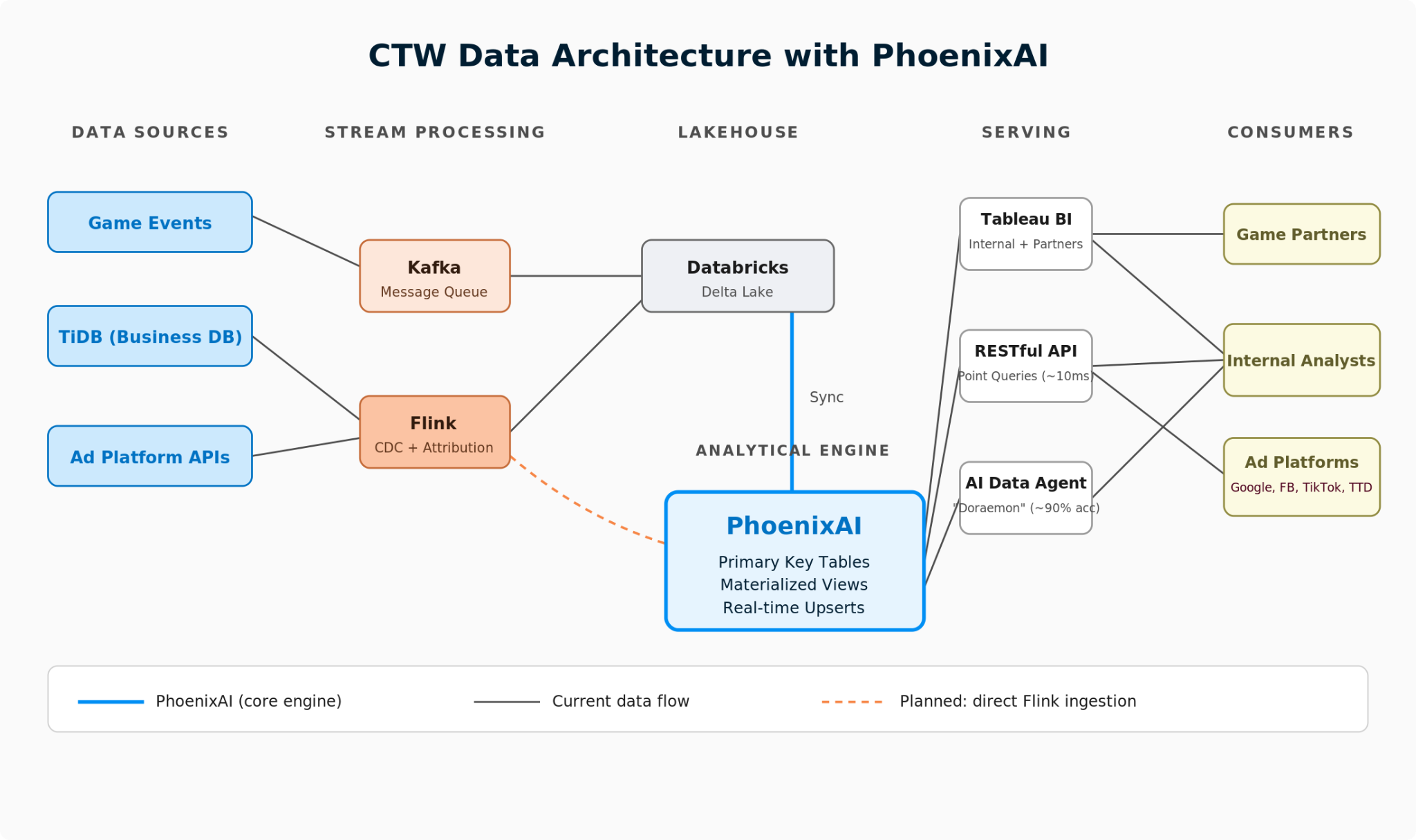
Real-Time Audience Segmentation with Primary Key Tables
For the audience-serving path, CTW adopted PhoenixAI Cloud's Primary Key table model. Instead of relying on large delete-and-replace refresh cycles, the team moved to a direct upsert-based serving pattern. For the representative large segments with millions of users, refresh time dropped from serveral hours to seconds.
The same serving layer now supports multiple downstream access patterns, including periodic batch delivery and low-latency reads. Downstream activation still varies by platform: Google is updated through periodic uploads, while The Trade Desk (TTD) uses a near-real-time server-to-server path. The online recommendation system accesses PhoenixAI through a RESTful API layer, where a common class of profile lookup requests involving light joins across two to three tables typically completes in the ~10 ms range.
Accelerated BI with PhoenixAI as a Serving Layer
For BI, CTW introduced PhoenixAI as a serving layer between its lakehouse and dashboard access path. Raw data lands in Delta Lake through Flink and Kafka pipelines, then synchronizes into PhoenixAI, where materialized views support interactive dashboard queries.
This decouples interactive BI traffic from lakehouse compute. In CTW's production environment, dashboard performance became significantly more stable under concurrent access, while reducing the need to scale lakehouse compute purely for dashboard serving.
CTW is also evaluating direct ingestion from Flink into PhoenixAI for selected real-time workloads. The motivation is operational simplicity and reliability: failures in intermediate CDC synchronization had previously made freshness monitoring across hundreds of tables difficult and operationally costly. A more direct Flink-to-PhoenixAI path could simplify the architecture and reduce an important class of synchronization risk.
AI-Powered Data Analysis Agent
Doraemon, CTW's internal data analysis agent, was initially built on Databricks and is now being migrated to StarRocks/PhoenixAI. The migration is driven by analytical workload requirements, including better join accuracy, faster query performance, and less need to maintain wide denormalized tables. During internal evaluation on representative real business questions, Doraemon achieved over 90% answer accuracy. CTW attributes this not only to model design, but also to strong metadata grounding and an analytical serving layer that better supports correct joins and fast execution.
To handle complex questions, CTW uses a multi-agent architecture. An orchestrator agent performs planning and task decomposition, then dispatches sub-agents to generate and execute SQL for individual sub-tasks. For decomposable questions, parts of the workflow can run in parallel, reducing overall response time.
CTW approaches agent quality as both a model and a data-governance problem. Doraemon is grounded in curated metadata, including schema descriptions, KPI definitions, semantic relationships, and validated query examples. Some of this metadata was originally sourced from Databricks Unity Catalog, but CTW standardized and repackaged it into an agent-ready knowledge layer that can be used consistently during planning and SQL generation.
A major challenge in analytical agents is semantic correctness. Even when SQL is executable, it can still be wrong if aggregation logic does not align with the underlying data grain and join structure. To address this, CTW encodes semantic constraints and business definitions directly into the agent's context, assisting the system generate SQL that is more consistent with both warehouse structure and business logic.
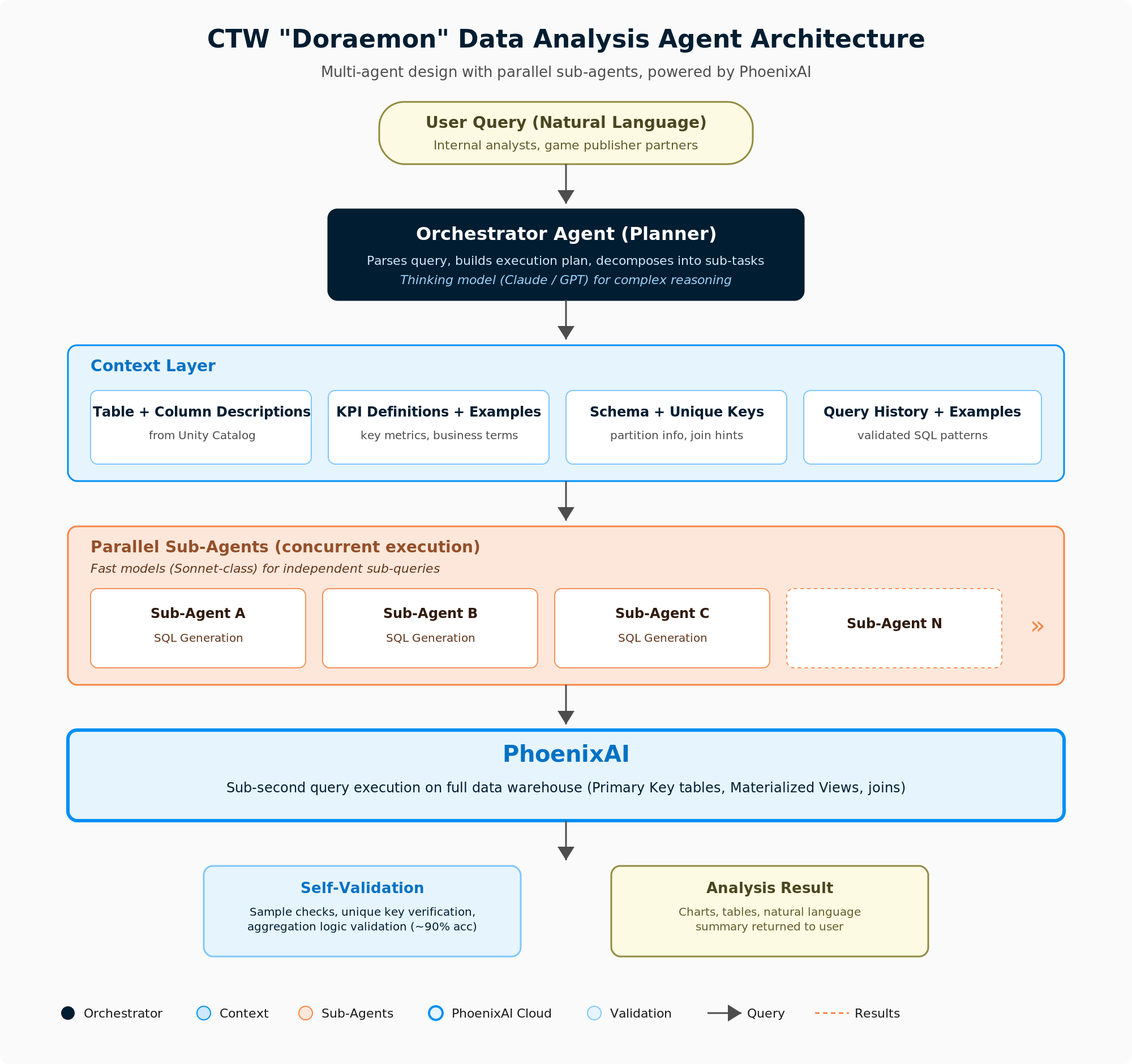
For context, the agent is grounded in structured metadata curated by CTW, including table and column descriptions, KPI definitions, and validated query examples. Some of the underlying schema metadata is sourced from Databricks Unity Catalog, but CTW packages this information into a form that the agent utilizes consistently during planning and SQL generation.
One of the key challenges was semantic correctness. In analytical workflows, aggregation logic has to align with the underlying data grain; otherwise, seemingly valid queries can still produce incorrect results. CTW addresses this by encoding key relationships and other semantic constraints into the agent's context, helping it choose aggregation logic that is consistent with warehouse structure and business definitions.
In CTW's internal evaluation on representative real business questions, the agent achieved over 90% answer accuracy under CTW's current evaluation methodology. CTW also uses workload-aware model routing, sending simpler tasks such as data sampling to faster models while reserving reasoning-heavy models for more complex planning.
The tech stack now in production:
The results
The migration delivered measurable improvements across all three workloads.
Audience Segment Updates: Hours to Seconds
Segment updates that took tens of hours on TiDB now complete in seconds. Data freshness for the audience table is under 10 seconds, enabling timely ad targeting across all integrated platforms.
BI Dashboard Response: 3x Faster
Tableau dashboards that took tens of seconds to load now render in a few seconds. The connection pool bottleneck is gone, and performance remains stable as data volume grows.
Cost Efficiency at Scale
CTW resolved a resource consumption issue with their Flink pipeline after the migration. Eliminating over-provisioned Databricks compute for BI query serving reduced infrastructure costs.
What's Next for CTW
CTW's roadmap focuses on two related themes: deeper serving-layer integration and more production-ready AI-native analytics.
On the infrastructure side, CTW is evaluating where deeper PhoenixAI integration can further simplify real-time serving paths, including more direct ingestion patterns and fewer intermediate synchronization layers.
On the AI side, CTW's view is that as model inference gets faster, query execution and data-serving latency become a larger share of the end-to-end agent experience. If model-side reasoning becomes fast while data access remains slow, the overall interaction still feels unresponsive. For many common analytical queries in CTW's current workloads, PhoenixAI already returns results in under a second. As model latency continues to improve, CTW sees a path toward reducing the full agent loop — from question to answer — to single-digit seconds for a broader set of interactive use cases, moving Doraemon closer to an interactive analytical assistant than a traditional batch-style reporting workflow.