About Conductor
This post is adapted from our recent webinar, How Conductor Builds Sub Second Agentic Analytics at Scale — watch the full session for the live demo and Q&A."
Conductor is an enterprise AEO (Answer Engine Optimization) platform that helps brands get found across AI and traditional search. Customers include Zoom, Citi, Louis Vuitton, Pfizer, and hundreds of other enterprise brands.
For a platform like Conductor, data is the product. Customers rely on real-time keyword rankings, SERP data, AI search citations, and website performance metrics to make marketing decisions worth millions of dollars. Every dashboard, every API response, and every AI-powered insight traces back to complex queries across terabytes of search and content data. The speed and accuracy of that data layer directly determines the quality of the customer experience.
You can't be "mostly right." You have to be right all the time. For precision data analytics, AI alone is not enough.
Key takeaway · Customer-facing precision isn't an 80% problem
The challenge
As Conductor's data needs scaled, three issues converged to push the team toward a full infrastructure redesign.
Fragmented Data Pipelines
Historically, data pipelines at Conductor were owned by individual feature teams. There was no centralized or standardized data layer. Each team built its own pipelines, creating growing complexity, cross-team dependencies, and no single source of truth. Cross-domain analysis required significant manual effort.
Hard Product Limits at the Data Layer
To meet performance requirements, Conductor relied on precomputed reports, pre-aggregating data to serve dashboards at acceptable speeds. This approach imposed hard limits on the customer experience: users couldn't freely slice and dice data across arbitrary time ranges or drill into row-level detail. Hard-coded insights created a rigid data model that couldn't scale with dynamic user requirements. The data journey from source to customer took days.
New Use Cases Demanded Sub-Second Performance
As Conductor's platform expanded into real-time analytics, synchronous API integrations, and agentic AI workflows, the requirements sharpened. The team identified four core use cases on top of their data lake: business intelligence, integration (synchronous and asynchronous API access), agentic workloads (MCP), and powering the application itself. Most of these needed sub-second real-time query performance on complex, ad-hoc queries across terabytes of unpartitioned data. Precomputed reports couldn't get there.
The solution
Building the New Data Architecture
Conductor's data team redesigned the infrastructure from the ground up, guided by five objectives: centralize data into a single source of truth, standardize modeling and ingestion patterns, democratize access for cross-functional teams, deliver data to customers instantly, and accelerate time-to-market for innovation.
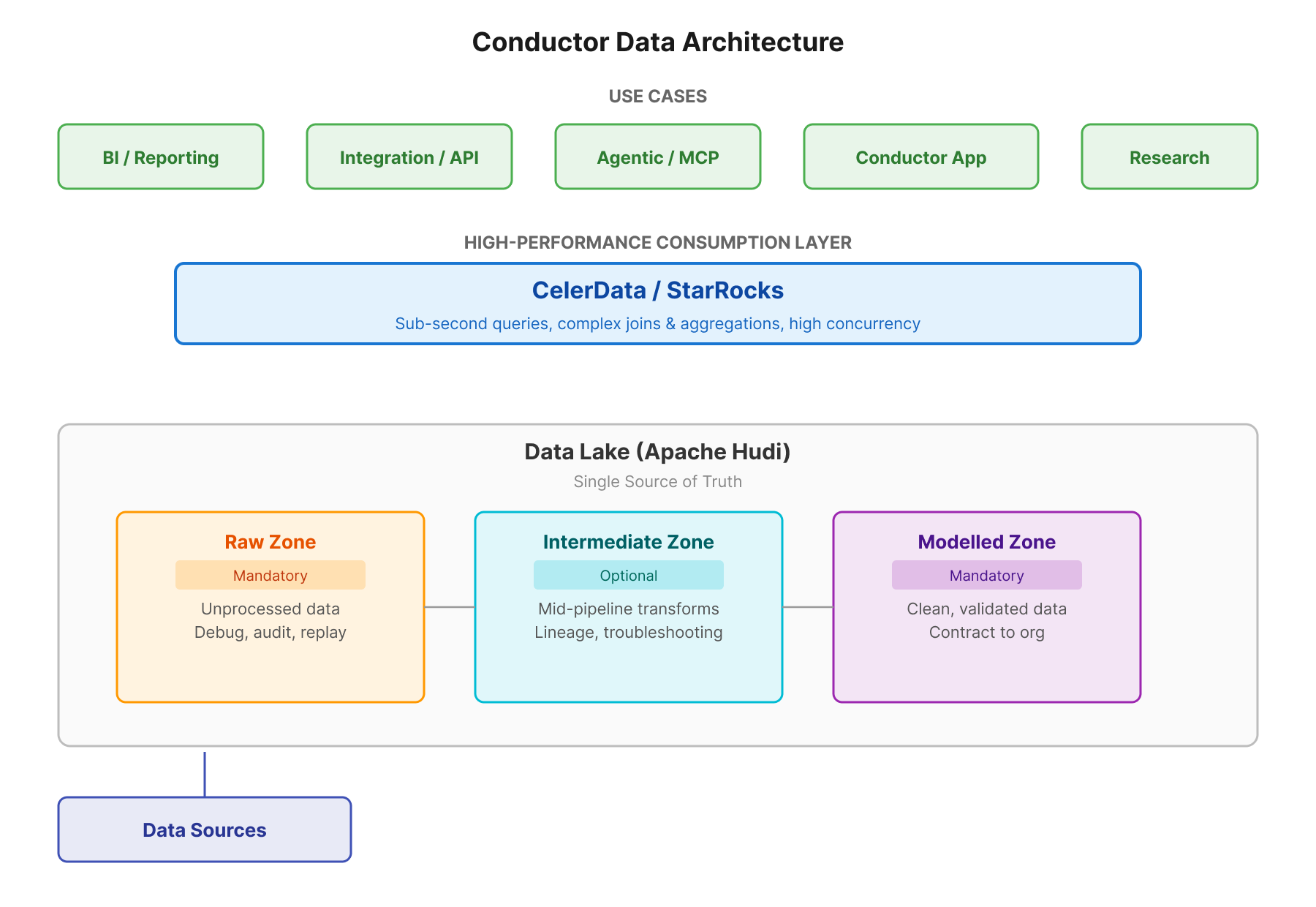
The foundation is a centralized data lake on Apache Hudi. Data flows through three zones: a raw zone (mandatory) that preserves data in its original, unprocessed form for debugging, auditing, and replaying pipeline events; an optional intermediate zone for mid-pipeline transformations to support lineage tracking and troubleshooting; and a modelled zone (mandatory) that delivers clean, validated, business-ready data. The modelled zone serves as the authoritative contract to the rest of the company, the single source of truth for all downstream consumers.
The High-Performance Consumption Layer
On top of the data lake, Conductor needed a high-performance consumption layer to serve all four use case categories: business intelligence and reporting, synchronous and asynchronous API integrations, agentic workloads (MCP), and powering the Conductor application itself.
This consumption layer is a decoupled architecture where use-case teams can model and query data independently while the data platform team manages the underlying datasets close to the domain. It enables use-case-specific data modeling with the performance characteristics each workload requires. The key requirements were clear: a high-performance query engine with support for complex joins and aggregations on large datasets, delivering sub-second latency at high concurrency.
Why PhoenixAI
After extensive research and testing across multiple scenarios and architectures, Conductor chose PhoenixAI as the engine for this consumption layer. Several factors drove the decision.
Strategic alignment. PhoenixAI engineers worked directly with Conductor's team to optimize queries and infrastructure. Feature requests flowed in both directions. Conductor found a true partnership, not just another vendor.
Data sovereignty. PhoenixAI's Bring Your Own Cloud (BYOC) model ensured Conductor retained 100% ownership of their data. The data never leaves Conductor's cloud environment.
Proven performance. PhoenixAI Cloud met the performance requirements for all core use cases during testing, delivering enterprise-grade real-time analytics with high concurrency and sub-second latency.
Optimized value. The performance-to-cost ratio was exceptional compared to the alternatives Conductor evaluated.
Powering Agentic Analytics with Split Reasoning
The most distinctive use case running on this infrastructure is Conductor's agentic analytics system, an MCP-based architecture that lets AI agents query Conductor's data with decimal-level accuracy.
The Problem with Typical MCP Implementations
Most MCP implementations follow a pattern where thin data pipes return raw or lightly aggregated data through APIs, and the LLM is left to stitch that data together, perform calculations, and produce analytics. This approach breaks at scale. LLMs hallucinate. They produce inconsistent results across runs. Even an 80% accuracy rate destroys trust in customer-facing analytics. As Conductor's team put it: you can't be "mostly right." You have to be right all the time. For precision data analytics, AI alone is not enough.
Split Reasoning Architecture
Conductor's solution is what they call a "split reasoning architecture": offloading each type of reasoning to the platform best suited for it.
LLM vs. Data API: Each Does What It's Good At
The LLM handles natural language understanding, intent interpretation, and deciding which tools to call with which parameters. The Data API handles everything that needs to be exact: joining datasets, running aggregations, and returning fully computed insights.
How a Request Flows
A user asks: "What is my brand market share for this topic against my competitors?" The LLM interprets the intent and calls the MCP tool with the right parameters. The Data API receives those parameters, executes the query against PhoenixAI Cloud, and returns a fully baked insight, not raw data. The LLM then presents the result in natural language. At no point does the LLM perform data stitching or arithmetic.
The MCP server is agent-agnostic. The same tools work across Claude, ChatGPT, Cowork, and Copilot.
Why This Is Hard on the Database
Every query is different. The Data API dynamically generates queries based on what the user asks. There is no precomputation, no caching of common queries. Each request hits PhoenixAI Cloud with a unique combination of joins, filters, and aggregations across terabytes of data, and it needs to return in sub-second to low-second time.
The tech stack now in production:
The results
The new architecture delivered improvements across performance, product flexibility, and development speed.
Sub-Second Analytics at Scale
Conductor now delivers second to sub-second query performance consistently on large datasets through PhoenixAI Cloud. Production workloads show queries scanning 6-7 GB of data across 180-240 million rows completing in 389ms to 2.8s, with many returning in under 1 second.
Data Freshness: Days to Hours
The end-to-end data latency, from data retrieval and processing to customer visibility, dropped from days to hours. The architecture can go even faster, but the team calibrates freshness against cost on a per-use-case basis.
Rapid Product Innovation
The decoupled architecture dramatically accelerated time to market. When Conductor launched AI Search Performance, a strategically critical new product, the team shipped the first version in less than two months. That timeline covered everything from net-new data pipelines through the high-performance consumption layer to the application. The same consumption layer architecture that powered keyword analytics was reused for the new AI search dataset with minimal additional work.
Eliminated Hard Limits
Precomputed reports are gone. Customers can now slice and dice data freely, selecting arbitrary time ranges up to two years, drilling into row-level detail, and comparing data points across time periods. The hard product limits that constrained the customer experience have been removed.
Decimal-Level Accuracy for AI Agents
Conductor's agentic analytics deliver results that match the front-end application to the decimal. Unlike typical LLM-based analytics that produce inconsistent results across runs, Conductor's split reasoning approach guarantees deterministic accuracy for every API-backed response. The LLM handles conversation and intent; PhoenixAI handles truth.
What's Next for Conductor
Conductor is continuously expanding the capabilities of their MCP tools, adding new insight types and supporting more granular filtering by category, search engine, and topic. The team is exploring fully agentic workflows where commands like "AEO Audit" trigger multi-step processes: the agent autonomously calls multiple tools, gathers data, and generates comprehensive reports with executive summaries, charts, and visualizations.
The broader vision is an analytics surface where marketers can ask natural language questions about their brand's AI search performance, sentiment, and competitive positioning, and receive answers backed by deterministic, sub-second queries against terabytes of real-time data. The LLM handles the conversation. PhoenixAI handles the truth.